
IOMETER PROFILE TESTING
Instead of our normal profile testing, which takes place at each QD, we’re running them a little different. The LSI Nytro MegaRAID needs hotspots to cache, so we run hot, warm, and cold zones on the drive. Each zone has it’s own test file, and the QD varies by zone. The important zone here is the hot, which runs at a QD of 32. Each test is performed with random data and takes 2 hours. In green, you can see the hot zone, while the cold and warm zones — characterized by less activity — are pretty much at the bottom, generating very few IOPS. We’ll use the same axis scale for each chart.
Each chart shows performance of just the HDDs by themselves. In between each and every run, we have to disassociate the cache from the HDDs, and in doing so erase everything on them. That way, when we run the next test, the Nytro card has to figure out which logical block addresses to cache all over. You can see this effect in the first several minutes of the test, which can take around 30 minutes to fully cache the file.
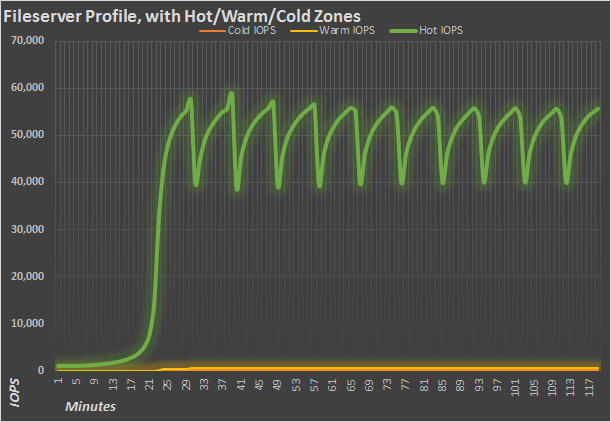
Over the two hours of the run, the fileserver profile shows an interesting wave pattern, with almost 15K IOPS between peak and trough, and recurring every 12 minutes or so. This is pretty strong performance for a fileserver profile, which is composed of .5K, 1K, 2K, 4K, 8K, 16K, 32K and 64K accesses with an 80/20 read write split. Read and write performance is fairly balanced.
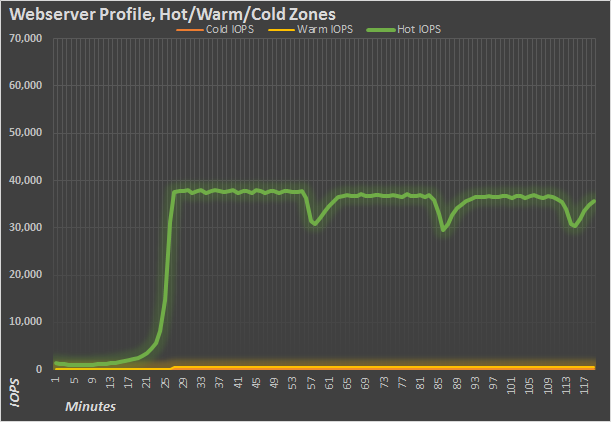
The webserver profile is composed of even more access sizes, running from .5K all the way up to 512K. Unlike the fileserver profile, the profile is 100% read, with no writes to get in the way. Once the test files are cached, the average IOPS generated are around 35K for minutes 27 through 120. The lion’s share of the accesses are .5K to 8K, with the bigger transfer sizes making up the minority.
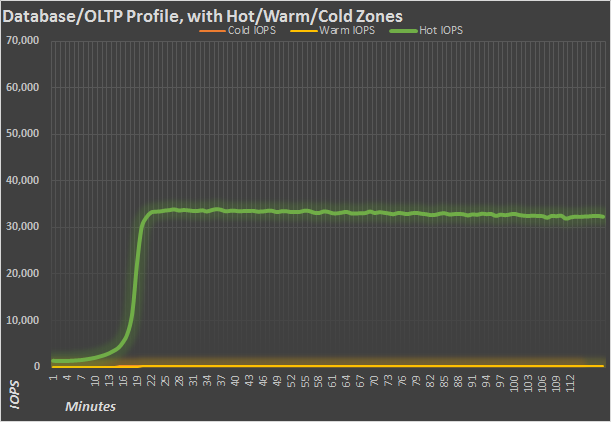
The database profile (8K, 50% read 50% write) is practically razor flat once the Nytro MegaRAID caches the test file. Obviously, in real life you wouldn’t delete the cache every couple hours, so the dynamic caching algorithm will decide which LBAs to keep in cache and which to evict in real time. If you notice the slight change in slope as the test moves on… recall the write saturation test from earlier. Despite the fact that we have a 740GB RAID 0 cache drive, filling up the cache drive does reduce performance, if only slightly in most circumstances.
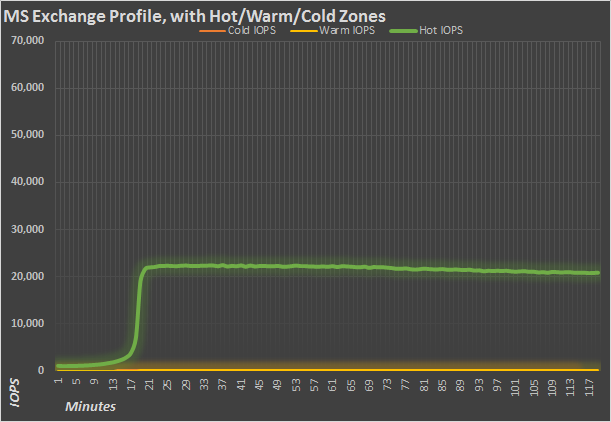
This isn’t one of the traditional server profiles, but instead is an emulation of a Microsoft Exchange 2010 email server. It’s 32K accesses on a 62% read/38% write split, designed to replicate the same disk activity that would be seen on a real Exchange server. It looks a lot like the database/oltp profile, just with lower transactions per second.
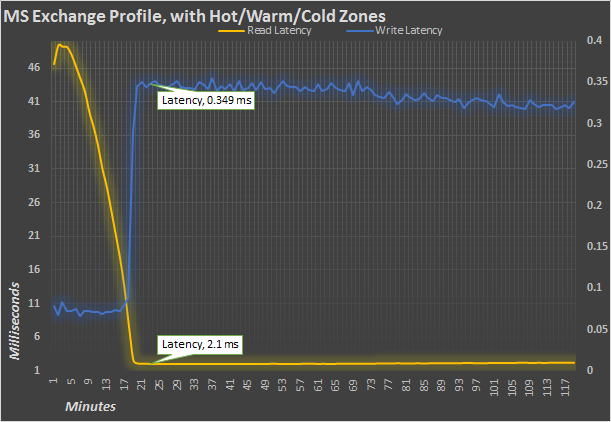
Since read and write latency is extremely important for Exchange servers, the above chart shows the average latency from the Exchange profile run. If read and write latency go above certain bounds, the server’s operation dependent on that IO will time out. Since the difference between read and write latency is so high, the read latency uses the axis on the left, while the write latency is plotted to the right axis.
As you’d expect, the caching does wonders for read latency, dropping it from ~50ms uncached to right around 2ms when cached. Write latency actually gets slightly worse, but the number of transactions per second skyrockets from a mere handful to over 20,000 once caching kicks in.
Just, WOW !
Another amazing review! Keep up the hard work. I’ve continued to be impressed by the rich content on this site.
Great looking piece from LSI and nice review Chris! What gets me though is the price of the unit. When you consider you can plug a SSD into a 9270 with CacheCade for a considrably cheaper end piece that 1 extra port gained for having onboard nand just doesn’t make fiscal sence.
What would be exciting would be to see the nitro’s flash set to 4 x X Gb units set in R0 nativly, (just like you can already using CacheCade and SSDs without the loss of more ports).
It’s great to see LSI developing their Pcie.3 offering and I look forward to where they take it in the future.