
Write saturation testing is normally performed with no preconditioning, over the whole drive. Since we can’t do that per-se, and because the actual hottest data is usually a much smaller percentage of the total array capacity, we’re using a 100GB test file. In between each run, we clear and disassociate the cache drives. Each run is five hours, though we’re just showing 240 minutes of that data here, and we test the cache drives in RAID 0 and RAID 1 with both random and repeating data.
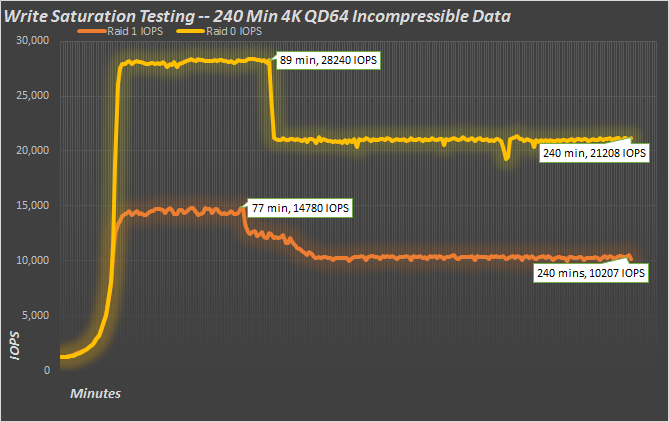
The first thing you’ll notice is that it takes around half an hour to fully cache the test file with all four runs. With random, incompressible data, we see a peak around 30 minutes, and then a write cliff. With only a 100GB hot-spot, it’s much like super-overprovisioning. In RAID 0, the two cache drives have 730GB of capacity and 28% overprovisioning. With random data, the controller can’t reduce the size of the data on the flash, so once it gets sufficiently filled, there are far fewer clean blocks to rely upon. When that happens, we get a write cliff. Beyond that point, the drive has to clean blocks on the fly, reducing performance and increasing latency. After 240 minutes, we’re averaging 21,208 IOPS in R0 and half that in R1. Since the R1 setup has half the available space, it ends up hitting the cliff a little sooner, while performance is roughly half of the R0 array.
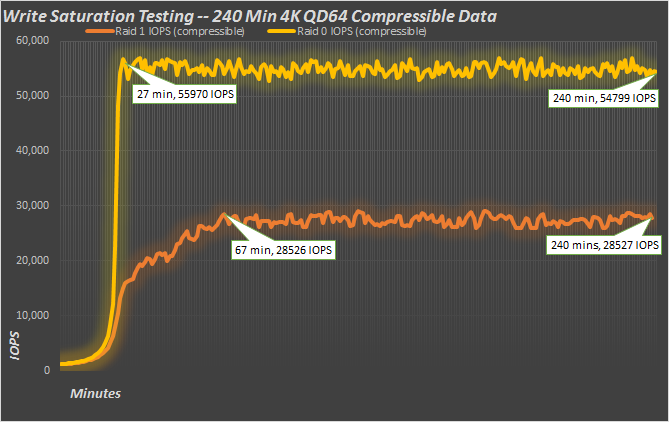
With the same 100GB test file but using easily compressible data, things look a lot different. With 100GB of repeating data, LSI SandForce compression technology can really reduce the amount of flash it takes to hold the cached data. With this data, the drive is only writing a small fraction of the total host writes, considerably extending the amount of space the drive has to work with when it comes to keeping fresh blocks available. Consequently, once the test file gets cached, it’s smooth sailing from there on out. At the end of the run, we have almost 55K 4K write IOPS in R0 and 28K in R1.
A different way to think of the caching mechanism in the Nytro MegaRAID is to consider it more a latency reduction machine, rather than something to just enhance IOPS. It certainly does both, but consider the following graph:
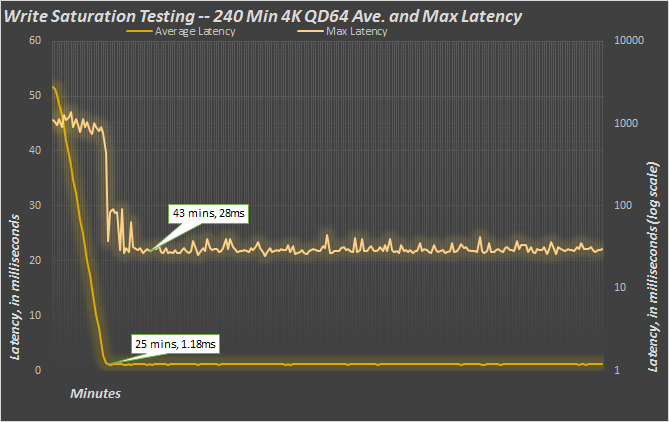
If we look at the R0 write saturation test from above, but only plot max and average latency, we see what happens as data is cached. The 15K Toshiba SAS drives are awesome, but average latency starts at over 50ms and max latency (shown on a logarithmic scale on secondary axis) starts at over 1 whole second. But that begins to change as the Nytro starts caching data. As the hit rate of the cache starts improving, latency starts dropping like a rock. Max latency improves from over 1000ms to 28ms at the 43 minute mark, and average drops from 50+ms to 1.18ms. That almost a 50x reduction in average and a 35x reduction in max latency. A stellar improvement with virtually no work. Just drop the Nytro MegaRAID card in and go.
Just, WOW !
Another amazing review! Keep up the hard work. I’ve continued to be impressed by the rich content on this site.
Great looking piece from LSI and nice review Chris! What gets me though is the price of the unit. When you consider you can plug a SSD into a 9270 with CacheCade for a considrably cheaper end piece that 1 extra port gained for having onboard nand just doesn’t make fiscal sence.
What would be exciting would be to see the nitro’s flash set to 4 x X Gb units set in R0 nativly, (just like you can already using CacheCade and SSDs without the loss of more ports).
It’s great to see LSI developing their Pcie.3 offering and I look forward to where they take it in the future.